
Page 297 - 《软件学报》2021年第9期
P. 297
吴森焱 等:融合多种特征的恶意 URL 检测方法 2921
基于以上分析可以看出:页面重定向跳转的特点主要体现在页面源代码和会话流程中,攻击者通过重定向
代码将用户导向恶意网站,以此来逃避检测引擎的跟踪.
3 恶意 URL 特征选择
特征选择的过程,即根据正常网站和恶意网站各方面的差异性选择具有明显区别度的特征.在本节中,我们
根据对真实存活的恶意 URL 的会话流程进行统计与分析.我们发现:在恶意 URL 的攻击流程中,存在客户端环
境识别、多次重定向跳转、典型的逃避检测行为以及发送有效攻击执行载荷等典型特点,因此,我们主要从 3
个方面设计特征,包括页面内容特征、JavaScript 函数参数特征和 Web 会话流程特征.
3.1 页面内容特征
在选取页面特征之前,我们首先从恶意样本公布网站 VirusShare(https://virusshare.com/)收集了近期公布的
真实恶意页面样本,而正常页面来源于 Alexa 中受欢迎的正常网站.我们借助于人工分析,发现这些恶意页面与
正常页面在 HTML 和 JavaScript 方面存在的差异.
正常页面在通常情况下页面整体 HTML 结构比较规范,页面中不会包含很多的特殊字符和敏感字符串;而
恶意页面在 HTML 结构上与正常页面相比存在较多的差异,例如,恶意页面中通常包含某些可利用的 HTML 标
签和存在风险的 JavaScript 函数,并且为了防止被检测引擎分析,恶意页面还会结合包括代码混淆、代码注入和
客户端环境识别等方式来逃避检测.攻击者通过混淆恶意代码来隐藏真正目的,从而逃避检测引擎,其中最常见
的混淆方式是对字符串做操作,如字符串的拆分替换和编码转义,以及加密等操作.
除了以上的差异,我们还发现:最新的恶意页面更多地结合了 HTML5 新出现标签和事件函数,以及恶意
VBScript 脚本代码进行攻击.此外,恶意 URL 还通过精心编写的恶意代码进行自动的重定向跳转,从而逃避检测
引擎的跟踪.同时,为了实现精准化地攻击特定用户人群,恶意 URL 在对用户进行攻击之前,还会通过多种方式
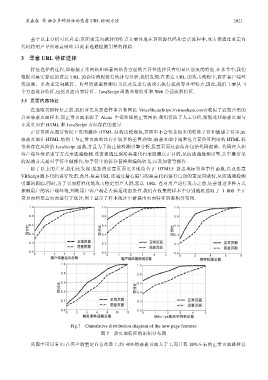
探测用户的客户端环境,判断用户客户端是否满足攻击条件.我们在收集的样本中分别随机选取了 1 000 个正
常页面和恶意页面进行了统计,图 7 显示了样本统计中新提出页面特征的累积分布图.
Fig.7 Cumulative distribution diagram of the new page features
图 7 新页面特征的累积分布图
从图中可以看出:在客户端重定向总次数上,约 40%的恶意页面大于 1,而只有 20%左右的正常页面跳转总