
Page 197 - 《软件学报》2021年第9期
P. 197
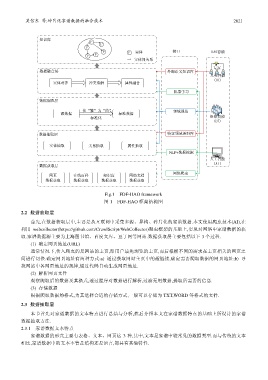
吴信东 等:碎片化家谱数据的融合技术 2821
知识库
P P
P
P P 实体 接口 HAO智能
P P
实体间关系
专家
数据融合层 外部语义知识库
人类智能
(HI)
实体对齐 冲突消解 属性融合
机器学习
数据规范层
化“繁”为“简” 领域规范
源数据 标准数据
标准化 组织智能
(OI)
数据抽取层 特定领域语料库
实体抽取 关系抽取 属性抽取
NLP+数据挖掘
人工智能
(AI)
数据获取层
网络爬虫
网页 在线百科 知识库 网络文档
数据获取 数据获取 数据获取 数据获取
Fig.1 FDF-HAO framework
图 1 FDF-HAO 框架结构图
2.2 数据获取层
首先,在数据获取层中,主要是从互联网中采集多源、异构、碎片化的家谱数据.本文使用爬虫技术(AI),在
利用 webcollector(https://github.com/CrawlScript/WebCollector)爬虫框架的基础上,实现对网络中家谱数据的获
取.家谱数据源主要为上海图书馆、百度文库、豆丁网等网站.数据获取层主要包括以下 3 个过程.
(1) 确定网页地址(URL)
通常情况下,传入爬虫的是网站的主页,即用户最先浏览的主页,而后根据不同的需求在主页相关的网页之
间进行切换.确定网页地址有两种方式:a) 通过获取网站主页中的超链接,确定需要爬取数据的网页地址;b) 寻
找网站中各网页地址的规律,通过代码自动生成网页地址.
(2) 解析网页文件
观察爬取后的数据及其格式,通过程序对数据进行解析,过滤无用数据,提取所需要的信息.
(3) 存储数据
根据爬取数据的格式,为其选择合适的存储方式,一般可以存储为 TXT,WORD 等格式的文件.
2.3 数据抽取层
本节首先对家谱数据的文本特点进行总结与分析,然后介绍本文在家谱数据特点的基础上所设计的家谱
数据抽取方法.
2.3.1 家谱数据文本特点
家谱数据的形式主要有表格、文本、网页这 3 种,其中,文本是家谱中较常见的数据类型.而与传统的文本
相比,家谱数据中的文本不管是结构还是语言,都具有其独特性.