
Page 77 - 《软件学报》2021年第8期
P. 77
孙乔 等:SW26010 众核任务并行调度系统及其嵌套并行算法应用 2359
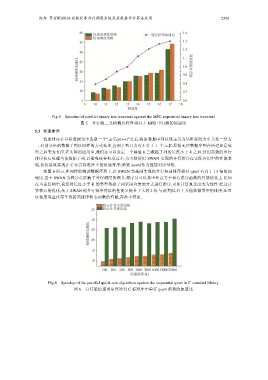
Fig.5 Speedup of parallel binary tree traversal against the MPE sequential binary tree traversal
图 5 并行版二叉树遍历程序相对于 MPE 串行版的加速比
5.3 快速排序
快速排序在目标数据集中选取一个“主元(pivot)”之后,将原数据序列以该主元为基准按照大小关系一分为
二.对划分出的数据子列以同样的方式处理,直到子列只含有不多于 1 个元素.原始无序数据序列在经过如是处
理之后变为有序.在实际的应用中,我们还可以设定一个阈值 K,当数据子列的长度小于 K 之后,使用高效的串行
排序核心处理当前数据子列,以避免任务粒度过小.为考察使用 SWAN 实现的并行排序在实际应用中的性能表
现,我们选取实现在 C 语言标准库中的快速排序(函数 qsort)作为性能对比基准.
如图 6 所示,在同样的测试数据序列上,以 SWAN 为基础实现的并行快速排序相对 qsort 有高于 13 倍的加
速比.由于 SWAN 为程序员屏蔽了并行调度的细节,程序员可以集中注意力于核心排序函数的性能优化上.比如
在当前算例中,我们对长度小于 K 的整型数据子列采用查表的方式进行排序,可使计算复杂度变为线性.经过计
算核心的优化,基于 SWAN 的并行排序算法的性能又提升了大约 2 倍.与此类似,对于其他数据类型的排序,还可
以使用向量化等手段提高排序核心函数的性能,在此不赘述.
Fig.6 Speedup of the parallel quick-sort algorithm against the sequential qsort in C standard library
图 6 并行版快速排序算法对 C 标准库中串行 qsort 函数的加速比