
Page 30 - 《软件学报》2021年第8期
P. 30
2312 Journal of Software 软件学报 Vol.32, No.8, August 2021
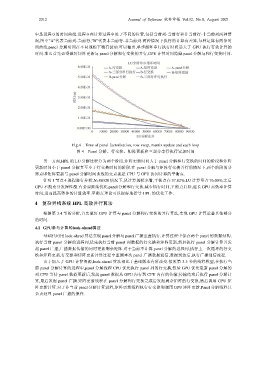
中是进程 0 的时间曲线.进程 0 在计算过程中处于不同的位置,包括当前列-当前行和非当前行-非当前列两种情
况,图中”A”代表当前列-当前行,”B”代表非当前行-非当前列.两种情况下执行的计算有差异,每种运算有两条时
间曲线.panel 分解时间在不同规模下稍有波动.可以看出,单步循环串行执行时间远大于 GPU 执行有效计算的
时间.那么首先必须做好矩阵更新与 panel 分解和行交换的并行,GPU 计算时间隐藏 panel 分解与和行交换时间.
Fig.4 Time of panel factorization, row swap, matrix update and each loop
图 4 Panel 分解、行交换、矩阵更新和三部分串行执行累加时间
另一方面,HPL 的 LU 分解过程分为两个阶段,矩阵更新时间大于 panel 分解和行交换的时间的阶段和矩阵
更新时间小于 panel 分解直至小于行交换时间的阶段.在 panel 分解与矩阵行交换并行的情况下,两个阶段的分
界点即矩阵更新与 panel 分解时间曲线的交点就是 CPU 与 GPU 协同计算的平衡点.
针对 1 节点 4 进程进行分析,N=88320 情况下,从计算规模来看,平衡点在 37.82%,LU 计算量占 76.00%,之后
GPU 不能充分发挥性能.有必要继续优化 panel 分解和行交换,减少执行时间,平衡点后移,延长 GPU 高效率计算
时间,进而提高整体的计算效率.平衡点理论可以很好地指导 HPL 的优化工作.
4 复杂异构系统 HPL 高效并行算法
根据第 3.4 节的分析,首先做好 GPU 计算与 panel 分解和行交换的并行算法,实现 GPU 计算重叠其他部分
的时间.
4.1 GPU参与计算的look-ahead算法
基础代码用 look-ahead 算法实现 panel 分解与 panel 广播重叠执行.计算过程中保存两个 panel 的数据结构.
执行当前 panel 分解的进程列,优先执行当前 panel 列数据的行交换和矩阵更新,然后执行 panel 分解计算并发
起 panel 广播,广播数据传输的同时更新剩余矩阵.对于当前不计算 panel 分解的进程列,执行上一次循环的行交
换和矩阵更新,行交换和矩阵更新计算过程中监测本次 panel 广播数据通信,数据到达后,执行广播通信流程.
由于加入了 GPU 计算资源,look-ahead 算法相比于基础版本有所改变.按照第 3.3 节的线程模型,在执行当
前 panel 分解计算的进程中,panel 分解线程 CPU 优先执行 panel 列的行交换,然后 GPU 优先更新 panel 分解的
列.CPU 等待 panel 数据更新后,发起 panel 数据从 GPU 内存到 CPU 内存的传输,传输结束后执行 panel 分解计
算,最后发起 panel 广播.矩阵更新线程在 panel 分解列行交换完成后发起剩余矩阵的行交换,然后调用 GPU 矩
阵更新计算.对于非当前 panel 分解计算进程,矩阵更新线程执行行交换和调用 GPU 矩阵更新.Panel 分解线程只
负责处理 panel 广播的操作.