
Page 287 - 《软件学报》2021年第8期
P. 287
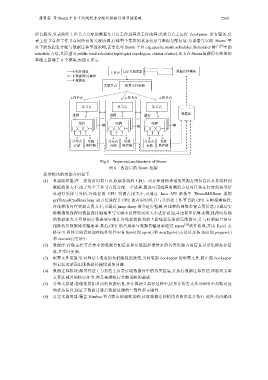
蒲勇霖 等:Storm 平台下的线程重分配与数据迁移节能策略 2569
后台服务,负责监听主控节点分配的数据并开启工作进程及工作线程;关联节点上运行 Zookeeper 后台服务,负
责主控节点和工作节点间所有的关联协调,存储整个集群的状态信息与数据分配信息.为部署与实现 Storm 平
[9]
台下的线程重分配与数据迁移节能策略,需要重写 Storm 平台 org.apache.storm.scheduler.IScheduler 接口 中的
schedule 方法,其原型为 public void schedule(topologies topologies, cluster cluster).本文在 Storm 集群原有框架的
基础上新增了 6 个模块,如图 6 所示.
拓扑部署 主节点 自定义调度器 数据迁移模块
数据读/写操作
数据流
关联节点 配置文件更新
工作节点 工作节点 工作节点
从节点 从节点 从节点
进程 进程 进程 数据库
线程 线程 线程
槽 槽 槽
分布式 负载 分布式 负载 分布式 负载
存储 监控器 存储 监控器 存储 监控器
Fig.6 Improved architecture of Storm
图 6 改进后的 Storm 框架
新增模块的功能介绍如下.
(1) 负载监控器:在一定的时间窗口内,收集各线程 CPU、内存和网络带宽的资源占用信息以及各线程间
数据流的大小.由于每个工作节点仅分配一个进程,因此可用线程监测的方法对任务运行时的各类信
息进行采样与分析.各线程的 CPU 资源占用大小,可通过 Java API 函数中 ThreadMXBean 类的
getThreadCpuTime(long id)方法获得其 CPU 的占用时间,并与其所处工作节点的 CPU 主频相乘获得;
各线程的内存资源占用大小,可通过 jmap -heap 指令进行检测;各线程的网络带宽占用信息,可通过实
际测得的线程间数据流传输速率与实验中设置的元组大小进行累加,并由简单估算求得;线程间传输
的数据流大小可使用计数器变量统计各线程接收到的上游线程发送的元组数量,并与时间窗口容量
相除获得数据流传输速率.最后,CPU 的占用率与数据传输速率通过 nmon [38] 软件获取,并由 Excel 表
格导出.具体实现需添加在拓扑组件中各 Spout 的 open(⋅)和 nextTuple(⋅)方法以及各 Bolt 的 prepare(⋅)
和 execute(⋅)方法中.
(2) 数据库:存储主控节点传来的数据分配信息和负载监控器传来的各类资源占用信息以及集群拓扑信
息,并实时更新.
(3) 配置文件更新:针对算法 2 造成的集群路径的改变,实时更新 Zookeeper 的配置文件,防止因 Zookeeper
的记忆功能而出现数据传输错误的问题.
(4) 数据迁移模块:部署算法 1 与算法 2,负责读取数据库中的各类信息,并执行数据迁移算法.该模块为本
文算法部署的核心环节,亦是集群执行节能策略的基础.
(5) 分布式存储:存储集群拓扑内的状态信息,并在算法 2 执行过程中,以异步的方式从 HDFS 中拉取对应
的状态信息,保证了数据迁移后数据处理的一致性和正确性.
(6) 自定义调度器:覆盖 Nimbus 节点默认的调度策略,读取数据迁移模块内的决策并执行.此外,代码编译