
Page 148 - 《软件学报》2021年第8期
P. 148
2430 Journal of Software 软件学报 Vol.32, No.8, August 2021
路口的车辆数目.这两种指标在计算过程中没有对不同车辆进行区分,更适合衡量路口整体效率,无法体现出特
殊车辆与普通车辆的差异.车辆通行时间是指车辆从驶入路网到驶出路网所用的时间,它虽然可以针对特殊车
辆与普通车辆分别计算,但它适用于在一轮训练结束后来计算,如果作为奖励函数指标每步计算的话,会有许多
车辆并没有驶出路网,此时计算结果就会有比较大的偏差.而车辆等待时间既可以对特殊车辆和普通车辆分别
计算,并且它不需要车辆驶出路网后才能计算,可以在智能体每一次执行动作后更新,因此本文采用车辆等待时
间作为奖励函数指标.同时,为了消除普通车辆与特殊车辆在数量上的差异所带来的影响,分别使用两种车辆的
平均等待时间作为优化指标.
令 N t,normal 表示在第 t 次动作执行结束后路口相连的入向道路上所有普通车辆的数量,N t,special 表示在第 t
次执行结束后路口相连的入向道路上所有特殊车辆的数量,W t 表示在第 t 次动作执行结束后观测到的第 i
i ,normal
辆普通车辆在该车道的累积等待时间,W i t ,special 表示在第 t 次动作执行结束后观测到的第 i 辆特殊车辆在该车道
的累积等待时间.普通车辆及特殊车辆的平均等待时间计算方式分别如式(4)、式(5)所示.
1
t
AVG _W normal = ⋅ ∑ t N ,normal W i t ,normal (4)
N t ,normal i= 1
1
t
AVG _W special = ⋅ ∑ t N ,special W i t ,special (5)
N t ,special i= 1
智能体在执行完第 t 次动作后得到的奖励就可以用式(6)计算得到,其中,α代表特殊车辆所占的权重,取值
区间为(0,1).
r = α (AVG _W t− 1 − AVG _W t ) (1 α ⋅ + − ) (AVG⋅ _W t− 1 − AVG _W t ) (6)
t special special normal normal
根据公式可以看出,如果在执行完一次动作之后,发现车辆的平均等待时间比上一次要小,这就意味着有部
分等待的车辆通过了路口,智能体将得到一个正值的 reward.强化学习算法的目标是使 reward 最大化,这就会使
平均等待时间朝着更小的方向优化.参数α可以用来调节特殊车辆与普通车辆在优化过程中所占的权重.
2.2 本文算法
2.2.1 Q 网络结构
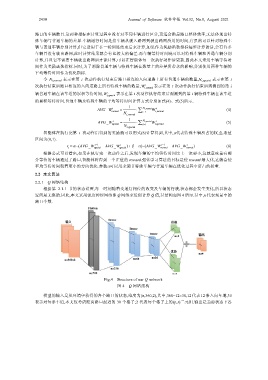
根据第 2.1.1 节的状态设置,每一时刻随着交通灯相位的改变及车辆的行驶,状态都会发生变化,所以状态
空间是无限的.因此,本文采用深度神经网络即 Q 网络来近似计算 Q 值,其结构如图 4 所示.其中,n 代表场景中的
路口个数.
Fig.4 Structure of our Q network
图 4 Q 网络结构
模型的输入是从环境中获得的各个路口的状态,维度为(n,360,2),其中,360=12×30,12 代表 12 条入向车道,30
表示对每条车道,本文仅考虑距离路口最近的 30 个格子;2 代表每个格子上的(p,s)二元组.输出是当前状态下各