
Page 10 - 《软件学报》2021年第8期
P. 10
2292 Journal of Software 软件学报 Vol.32, No.8, August 2021
调用次数.针对这些函数,本文应用多种优化策略对 BLIS 库中的各级 BLAS 函数进行了优化,获得了性能的大幅
度提升,提高了异构 HPL 的效率,更好地发挥了异构系统的性能.
1.2 异构单元处理器概述
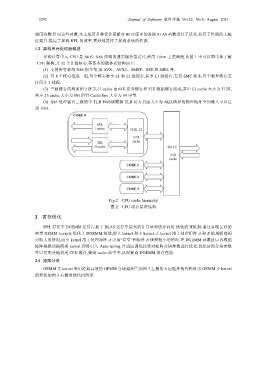
异构计算单元 CPU 是 64 位 X86 架构的通用服务器芯片,采用 14nm 工艺制造.从图 1 中可以简单地了解
CPU 架构,共 32 个计算核心.其基本的微体系结构如下:
(1) 支持所有标准 X86 指令集,如 AVX、AVX2、SMEP、SSE 和 SSE2 等.
(2) 每 4 个核心组成一组,每个核心独享 L1 和 L2 级缓存,共享 L3 级缓存,支持 SMT 技术,每个物理核心支
持同步 2 线程.
(3) 三级缓存结构如图 2 所示,L1 cache 由 64K 指令缓存和 32K 数据缓存组成,其中 L2 cache 大小为 512K,
共享 L3 cache 大小为 8M.所有 Cache line 大小为 64 字节.
(4) X86 处理器有三级指令 TLB 和两级数据 TLB.访存页面大小为 4KB,映射的物理地址空间最大可以达
到 1GB.
Fig.2 CPU cache hierarchy
图 2 CPU 缓存层次结构
2 访存优化
HPL 算法中 DGEMM 运算占据了 BLAS 运算中最大的计算量和访存耗时.优化的 HBLIS 通过实现互补的
两类 GEMM kernels 优化了 DGEMM 性能,即大 kernel 和小 kernel.大 kernel 用于处理矩阵 A 和 B 的规模都相
对较大的情况,而小 kernel 用于处理矩阵 A 更加“高窄”和矩阵 B 规模较小的情况.在 DGEMM 函数接口内根据
矩阵规模切换两类 kernel.同时引入 Auto-tuning 自适应调优技术对矩阵分块参数进行优化,优化后的分块参数
可以更充分地利用 CPU 缓存,提高 cache 命中率,从而提高 DGEMM 访存性能.
2.1 矩阵分块
[8]
GEMM 大 kernel 采用经典高效的 GEMM 分块算法 ,如图 3 左侧的 6 层循环伪代码所示;GEMM 小 kernel
的算法如图 3 右侧的伪代码所示.