
Page 219 - 《软件学报》2020年第11期
P. 219
3534 Journal of Software 软件学报 Vol.31, No.11, November 2020
3000-01-01.在进行时序分区操作时,采样阈值设定为 5%.实验的硬件环境为:Intel(R)Core(TM)i7-7700 CPU@
3.60GHz,8 核 CPU,8GB 内存,硬盘 2T;软件环境为:64 位 Win10 操作系统,编程语言 Java,底层数据库 MySQL5.7.
5.1 TPindex磁盘索引构建
通过上述的理论说明,经过时序分区和线序划分的操作之后,时态数据均匀且具有一定顺序结构的分布在
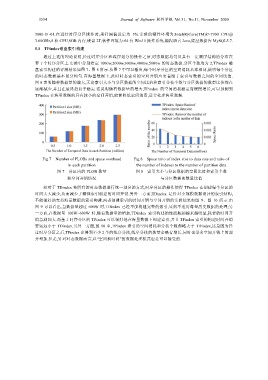
若干个时序分区上.实验中分别给定 1000w,2000w,3000w,4000w,5000w 的时态数据,分区个数均为 2,TPindex 磁
盘索引构建的评测结果如图 7、图 8 所示.从图 7 中可以看出,每个时序分区的空间消耗基本相同,说明每个分区
的时态数据基本划分均匀.在海量数据下,此时时态索引的空间开销应更着眼于索引与数据之间的空间比值.
图 8 表明随着数据量的增大,无论索引大小与分区数据的空间比值和索引分枝个数与分区数据的数量比值都在
逐渐减少,并且在最终趋向于稳定.这说明随着数据量的增大,TPindex 的空间消耗稳定而缓慢增长,可以预测到
TPindex 在海量数据的具有较小的空间开销,能够降低空间浪费,适合处理海量数据.
Fig.7 Number of PLOBs and space overhead Fig.8 Space ratio of index size to data size and ratio of
in each partition the number of indexes to the number of partition data
图 7 分区内的 PLOB 数量 图 8 索引大小与分区数据的空间比值和索引个数
和空间开销情况 与分区数据的数量比值
相对于 TDindex 将所有的时态数据进行统一划分的方式,时序分区的操作使得 TPindex 在创建每个分区的
时间大大减少,从而减少了整体索引创建的时间开销.另外一方面,TDindex 是针对小规模数据设计的索引结构,
不能很好地支持海量数据的索引构建.两者创建索引的时间开销与空间开销的实验结果如图 9、图 10 所示.由
图 9 可以看出,当数据量超过 600W 时,TDindex 已经不能构建完整的索引,显然不适用海量历史数据的处理;另
一方面,在数据量 100W~600W 时,随着数据量的增加,TDindex 索引构建的性能瓶颈越来越明显,耗费的时间开
销急剧加大.而基于时序分区的 TPindex 可以很好地在海量数据下创建索引,并且 TPindex 索引的构建时间开销
要远远小于 TDindex.另外一方面,图 10 中,TPindex 索引的空间消耗和分枝个数都略大于 TDindex,这是因为经
过时序分区之后,TPindex 会得到至少 2 个的线序分枝,线序分枝的数量会略有增长,同时也带来空间开销上的部
分增加.但是,针对时态数据而言,以“空间换时间”的数据处理模式也是可以接受的.