
Page 213 - 《软件学报》2020年第11期
P. 213
3528 Journal of Software 软件学报 Vol.31, No.11, November 2020
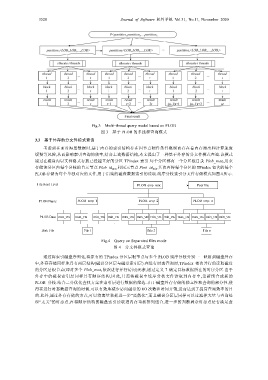
Fig.3 Multi-thread query model based on PLOB
图 3 基于 PLOB 的多线程查询模式
3.3 基于外存的分文件模式查询
考虑到在面对海量数据时,基于内存的索引结构存在因节点硬件条件限制而存在着内存溢出和计算速度
缓慢等风险,从而影响索引查询的效率,结合上述数据结构,本文提出了一种基于外存的分文件模式查询.该模式
通过在磁盘内以文件格式存放已经建立好的分区 TPindex 索引.每个分区都有一个分区根目录 Plob_root i ,用来
存储该分区内每个分枝的首元节点 Plob_td max 和尾元节点 Plob_td min .其次再将每个分区的 TPindex 包含的每个
PLOB 存储为每个单独对应的文件,用于后续的磁盘数据索引的读取.线序分枝索引分文件存储模式如图 4 所示.
Fig.4 Query on Separated files mode
图 4 分文件模式查询
通过将索引磁盘序列化,将原有的 TPindex 分区层根节点与多个 PLOB 线序分枝分别一一映射到磁盘外存
中,外存存储同样地具有两层结构(磁盘分区层与磁盘索引层).在进行时态查询时,TPindex 依次并行的读取磁盘
的分区层根节点(即对多个 Plob_root i 依次进行并行访问)元素,通过定义 7 确定目标数据所在的时序分区.由于
外存中的磁盘索引层同样具有顺序结构,因此,只需将磁盘中线序分枝文件读取到内存中,重新组合成新的
PLOB 分枝.结合二分优化查找方案在索引层进行数据的筛选..由于磁盘外存存储的独立性和查询的部分性,使
得在进行时态数据查询的时候,可以有效地减少访问磁盘的 I/O 次数和时间开销,进而达到了提高查询效率的目
的.此外,通过外存存储的方式,可以将海量数据进一步“离散化”,而且磁盘分区层同样可以过滤掉大量与查询处
理“无关”的时态点,再将顺序结构的磁盘索引读取进内存重新排列组合,进一步的判断剩余时态点是否满足查