
Page 137 - 《软件学报》2020年第11期
P. 137
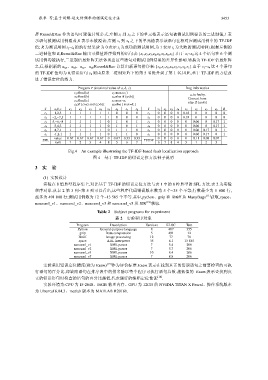
张卓 等:基于词频-逆文件频率的错误定位方法 3453
择 Russel&Rao 作为语句可疑值计算公式.左侧 s 1 到 s 8 之下的单元格表示语句被测试用例覆盖的二进制值,1 表
示语句被测试用例覆盖,0 表示未被覆盖;右侧 s 1 到 s 8 之下的单元格表示该语句在相对应测试用例中的 TF-IDF
值; R 为测试用例 t 1 ~t 6 的执行结果(R 为 0 表示 t i 为成功的测试用例,为 1 表示 t i 为失败的测试用例).根据左侧的
二进制值和 R,Russel&Rao 输出可疑值降序排列的语句表:{s 1 ,s 2 ,s 3 ,s 4 ,s 6 ,s 7 ,s 8 ,s 5 }.由于 s 1 ~s 4 这 4 个语句在 6 个测
试用例均被执行,二进制信息矩阵无法体现出这些语句对测试用例结果的差异性影响.转换为 TF-IDF 信息矩阵
之后,根据新的 a np 、a nf 、a ep 、a ef ,Russel&Rao 计算出新语句排序表:{s 6 ,s 7 ,s 8 ,s 4 ,s 5 ,s 1 ,s 2 ,s 3 }.由于 s 1 ~s 4 这 4 个语句
的 TF-IDF 值均为 0,错误语句 s 6 则由原来二进制矩阵下的第 5 名提升到了第 1 名.因此,基于 TF-IDF 的方法改
进了错误定位的效力.
Progarm P (maximal value of a, b, c) Bug information
s 1:Read(a) s 5:max=c;} s 6 is faulty.
s 2:Read(b) s 6:else if (a<b){ Correct from:
s 3:Read(c) s 7:max=a; else if (a>b){
s 4:if (c>a) and (c>b){ s 8:else {max=b;}
T a,b,c s 1 s 2 s 3 s 4 s 5 s 6 s 7 s 8 T s 1 s 2 s 3 s 4 s 5 s 6 s 7 s 8 R
t 1 1,2,3 1 1 1 1 1 0 0 0 t 1 0 0 0 0 0.18 0 0 0 0
t 2 −2,−7,5 1 1 1 1 1 0 0 0 t 2 0 0 0 0 0.18 0 0 0 0
t 3 5,−6,−8 1 1 1 1 0 1 0 1 t 3 0 0 0 0 0 0.06 0 0.17 1
5,4,3 1 1 1 1 0 1 0 1 0 0 0 0 0 0.06 0 0.17 1
t 4 t 4
t 5 4,7,1 1 1 1 1 0 1 1 0 t 5 0 0 0 0 0 0.06 0.17 0 1
t 6 -1,2,1 1 1 1 1 0 1 1 0 t 6 0 0 0 0 0 0.06 0.17 0 1
value 0.67 0.67 0.67 0.67 0 0.67 0.33 0.33 0 0 0 0 0 0.11 0.08 0.07
SFL TFIDF
rank 1 2 3 4 8 5 6 7 6 7 8 4 5 1 2 3
Fig.4 An example illustrating the TF-IDF-based fault localization approach
图 4 基于 TF-IDF 的错误定位方法例子说明
3 实 验
(1) 实验设计
实验在 8 组典型程序集上,对比基于 TF-IDF 的错误定位方法与表 1 中的 8 种典型的 SFL 方法.表 2 为实验
程序对象.从表 2 第 3 列~第 5 列可以看出,这些程序代码错误版本数为 5 个~35 个不等;行数最少为 5 000 行,
最多为 491 000 行;测试用例数为 12 个~13 585 个不等.其中,python、gzip 和 libtiff 从 ManyBugs [11] 获取,space、
nanoxml_v1、nanoxml_v2、nanoxml_v3 和 nanoxml_v5 从 SIR [12] 获取.
Table 2 Subject programs for experiment
表 2 实验程序对象
Program Description Versions KLOC Test
Python General-purpose language 8 407 355
gzip Data compression 5 491 12
libtiff Image processing 12 77 78
space ADL interpreter 35 6.1 13 585
nanoxml_v1 XML parser 7 5.4 206
nanoxml_v2 XML parser 7 5.7 206
nanoxml_v3 XML parser 10 8.4 206
nanoxml_v5 XML parser 7 8.8 206
实验采用错误定位精度(称为 Exam) [13] 作为评价标准.Exam 表示在找到真正的错误语句之前要检查的可执
行语句的百分比,即缺陷语句在排序表中的排名除以整个程序可执行语句总数.越低值的 Exam,表示查找到真
正的错误语句时检查的语句的百分比越低,代表越好的缺陷定位性能 [14] .
实验环境为:CPU 为 I5-2640、16GB 物理内存、GPU 为 12GB 的 NVIDIA TITAN X Pascal、操作系统版本
为 Ubuntu16.04.3、matlab 版本为 MATLAB R2016b.