
Page 203 - 《高原气象》2026年第2期
P. 203
2 期 卢 姝等:融合地形特征和神经网络的日最高/最低气温预报订正方法研究 503
2. 3 数据预处理 域。具体做法(Hartigan and Wong, 1979)是以空间
数据预处理步骤对模型精度的提高发挥着重 中 k 个中心进行聚类, 对最靠近他们的对象归类,
要作用。在建模前, 需要对预报与观测数据进行数 通过迭代的方法, 逐次更新聚类中心的值, 直至得
据清洗。因ECMWF预报产品高空与地面要素空间 到最好的聚类结果, 实现的目标函数是:
分辨率不一致, 本文采用双线性插值方法将上述产 n
2
min (c 1 ,c 2 ,⋯,c k ) ∑ d [ X i ,C ( X i ) ] (2)
品统一插值至0. 05°×0. 05°分辨率, 以匹配观测数据 i = 1
网格。ECMWF 预报产品中存在少数日期缺失, 采 式中: c , c , …, c 分别为 k 个簇的中心; C(X)表
i
1
k
2
2
用线性插值方式填补时间序列中缺失数据, 并从中 示 X 是所属类的中心点; d 为 X 与 C(X)两点距离
i
i
i
挑选与观测数据对应的时间以保持预报与观测时间 的平方。
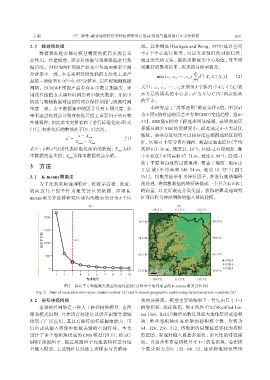
维度一致。由于数据集中的因子具有不同尺度, 如 本研究基于“肘部法则”确定最佳 k 值, 图 2(a)
果不经过处理会导致在较低尺度上重要因子的有效 为不同k值对应的误差平方和(SSE)变化趋势, 当k>
性被稀释, 因此本文对所有因子进行标准化处理[式 3 时, SSE 随 k 值的下降速率明显减缓, 表明增加更
(1)], 标准化后的数值处于[0, 1]之间。 多簇对减少 SSE 的贡献变小, 因此选定 k=3 为最优
簇数。聚类分区结果可以较好反应湖南地形区划特
x = x - X min (1)
*
X max - X min 征, 区域-1主要分布在湘西、 湘南山地山原区(平均
式中: x和 x*分别代表标准化前后的数据; X max 为样 高程813. 30 m, 坡度21. 16°); 区域-2对应湘北、 湘
本数据的最大值; X 为样本数据的最小值。 中平原区(平均高程 97. 71 m, 坡度 6. 98°); 区域-3
min
处于平原和山地的过渡地带, 覆盖了湘西、 湘南山
3 方法
丘区域(平均高程 348. 54 m, 坡度 16. 35°)[图 2
3. 1 K-means聚类法 (b)]。将聚类结果作为特征因子, 并进行独热编码
为了反映实际地理特征, 将数字高程、 坡度、 预处理, 将离散数值的特征转换成一个只含有0和1
坡向这几个因子作为聚类分区的依据, 应用 K- 的向量, 以更好表达分类变量。获得的聚类地理特
means 聚类算法将研究区域内的格点划分为 k 个区 征可以作为神经网络的输入帮助建模。
图2 误差平方和随聚类数量的变化趋势(a)和基于地理变量的K-means聚类分区(b)
Fig. 2 Sum of squared errors versus cluster number (a) and K-means geographic partitioning based on terrain variables (b)
3. 2 卷积神经网络 致的分辨率。模型主要结构如下: 首先由尺寸 3×3
卷积神经网络是一种人工神经网络模型, 在图 的卷积核、 批标准化、 修正线性单元(Rectified Lin‐
像和模式识别、 自然语言处理以及语音识别等领域 ear Unit, ReLU)激活函数以及最大池化层组成卷积
得到了广泛应用, 其具有独特的特征提取能力, 可 块, 堆叠卷积块时逐步增加卷积核个数, 分别为
以自动从输入图像中提取关键的空间特征。本文 64、 128、 256、 512, 将数据的局部信息转化为高阶
设计了多个卷积块组成的 CNN 模型(图 3), 将 EC‐ 特征图, 实现对输入数据多层次、 多尺度的特征提
MWF 预报因子、 临近观测因子和地表特征进行组 取。再逐步堆叠卷积核尺寸 1×1 的卷积块, 卷积核
合输入模型, 上述特征已经被上采样至与真值场一 个数分别为 256、 128、 64、 32, 逐步降低特征图维