
Page 194 - 《高原气象》2026年第2期
P. 194
高 原 气 象 45 卷
494
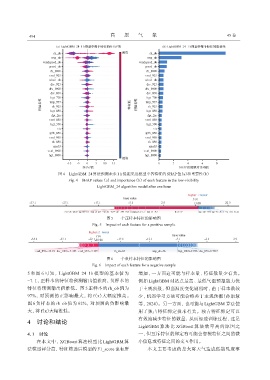
图4 LightGBM_24算法预测未来1 h低能见度模型中各特征的SHAP值(a)和重要性(b)
Fig. 4 SHAP values (a) and importance (b) of each feature in the low-visibility
LightGBM_24 algorithm model after one hour
图5 一个正样本特征的影响图
Fig. 5 Impact of each feature for a positive sample
图6 一个负样本特征的影响图
Fig. 6 Impact of each feature for a negative sample
5 和图 6 可知, LightGBM_24_1h 模型的基本值为 增加, 一方面这可能与样本量、 特征数量少有关。
-7. 1, 正样本的特征将预测输出值推高, 负样本的 例如 LightGBM 对站点最高、 最低气温预报能力优
特征将预测输出值推低。图 5 正样本的 rh_ob 值为 于主观预报, 但当温度变化剧烈时, 由于样本数较
97%, 对预测的正影响最大, 将 f(x)大幅度推高。 少, 机器学习方法可能会略差于主观预报(孙康慧
图 6 负样本的 rh_ob 值为 62%, 对预测的负影响最 等, 2024)。另一方面, 也可能与 LightGBM 算法使
大, 将f(x)大幅推低。 用了独占特征绑定技术有关。独占特征绑定可以
有效地减少特征的数量, 从而加速训练过程, 这是
4 讨论和结论
LightGBM 算法比 XGBoost 算法效率高的原因之
4. 1 讨论 一, 但互斥特征的绑定有可能会忽视特征之间的微
在本文中, XGBoost 算法模型比 LightGBM 算 小信息或特征之间的交互作用。
法模型评分高, 特征筛选后模型的 F1_score 也有所 本文主要考虑的是大雾天气造成低能见度事