
Page 222 - 《软件学报》2020年第9期
P. 222
郭肇强 等:基于信息检索的缺陷定位:问题、进展与挑战 2843
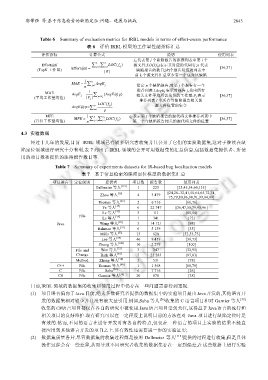
Table 6 Summary of evaluation metrics for IRBL models in terms of effort-aware performance
表 6 评价 IRBL 模型的工作量性能指标汇总
评估指标 计算公式 说明 使用列表
f ij 代表第 j 个缺陷报告的推荐列表中第 i 个
n k
Effort@K j= ∑∑ i= 1 LOC ()f ij 源文件;LOC(f ij)表示其对应的代码行;n 代表
1
(TopK 工作量) Effort@k = | R | 缺陷报告的数目;|R|个报告对应的列表中 [36,37]
前 k 个源文件汇总至少有一个包含该缺陷
1
MAE = ∑ n AvgE
n j= 1 j 给定 n 个缺陷报告,对第 j 个报告有一个
MAE AvgE j = 1 ∑ {AvgE @ } p 推荐列表 l.AvgE j 表示对报告 j,找出所有
∈
(平均工作量均值) | P j | pP j 相关文件平均所需花费的工作量;P j 表示 [36,37]
推荐列表 l 中所有与缺陷报告相关的
ij f
AvgE @ p= ∑ p LOC p () 源文件位置的集合
1
i=
MFE MFE = 1 n j= ∑∑ j q LOC () q j 表示第 j 个缺陷报告的源代码文件推荐列表中
ij f
(首位工作量均值) n 1 i= 1 第一个与缺陷报告相关的源代码文件的位置 [36,37]
4.3 实验数据
经过十几年的发展,目前 IRBL 领域已有较多研究者收集并且公开了它们的实验数据集,这对于继续在缺
陷定位领域进行研究十分有利.表 7 列出了 IRBL 领域的公开可用数据集的汇总信息,包括数据集提供者、所使
用的项目数和提供的缺陷报告数目等.
Table 7 Summary of experiments datasets for IR-based bug localization models
表 7 基于信息检索的缺陷定位模型的数据集汇总
项目语言 定位级别 提供者 项目数 报告数 使用列表
Dallmeier 等人 [115] 1 223 [23,45,54,60,115]
Zhou 等人 [28] 4 3 479 [24,28−32,41,50,64,65,72,74,
75,79,80,86,90,91,93,94,99]
Thomas 等人 [66] 2 6 716 [66,76]
Ye 等人 [47] 6 22 747 [36,47,55,79,95,96]
Le 等人 [45] 3 111 [45,54]
File [72]
Le 等人 1 341 [72]
Java Wang 等人 [98] 3 14 121 [98]
Rahman 等人 [35] 6 5 139 [35]
Mills 等人 [53] 13 620 [52,53,73]
Lee 等人 [39] 46 9 459 [39,73]
Zhang 等人 [100] 10 2 279 [100]
File and Wen 等人 [32] 3 347 [32,95]
Change Rath 等人 [83] 7 25 283 [97,83]
Method Zhang 等人 [78] 5 531 [78]
C++ File Thomas 等人 [66] 1 1 368 [66,76]
C File Saha [26] 6 7 716 [26]
C# File Garnier 等人 [38] 20 878 [38]
目前,IRBL 领域的数据集的收集和使用过程中仍存在一些问题需要得到重视.
(1) 项目语言偏向于 Java.目前,绝大多数研究者提供的数据集中的实验项目是由 Java 开发的,其他语言开
发的数据集相对较少并且没有被大量引用.例如,Saha 等人 [26] 收集的 C 语言项目和对 Garnier 等人 [38]
收集的 C#语言项目都仅在各自的研究中被使用.Java语言项目受到关注,这得益于 Java语言的流行和
相关项目的良好维护.现有研究可以在一定程度上说明目前的方法在对 Java 项目进行缺陷定位时是
有效的.然而,不同的语言在进行开发时有各自的特点,仅仅在一种语言的项目上实验的结果不能直
接应用到其他语言开发的项目之上.其有效性还需要进一步的实验证实;
(2) 数据集质量各异.尽管数据集的收集过程都是按照 Dallmeier 等人 [115] 提供的过程进行收集,但是具体
操作过程会有一些差异,从而导致不同研究者收集的数据集存在一定到偏差,在这些数据上进行实验