
Page 341 - 《软件学报》2020年第10期
P. 341
高珑 等:并行帧缓存设备:基于多核 CPU 的 Xorg 并行显示优化 3317
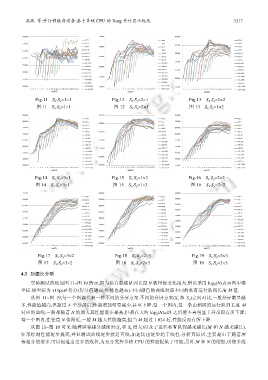
Fig.11 S x ⋅S y =1×1 Fig.12 S x ⋅S y =2×1 Fig.13 S x ⋅S y =1×2
图 11 S x ⋅S y =1×1 图 12 S x ⋅S y =2×1 图 13 S x ⋅S y =1×2
Fig.14 S x ⋅S y =3×1 Fig.15 S x ⋅S y =1×3 Fig.16 S x ⋅S y =2×2
图 14 S x ⋅S y =3×1 图 15 S x ⋅S y =1×3 图 16 S x ⋅S y =2×2
Fig.17 S x ⋅S y =3×2 Fig.18 S x ⋅S y =2×3 Fig.19 S x ⋅S y =3×3
图 17 S x ⋅S y =3×2 图 18 S x ⋅S y =2×3 图 19 S x ⋅S y =3×3
4.2 加速比分析
实验测试曲线如图 11~图 19 所示,因为私有就绪队列长度 N 数量级变化很大,所以采用 log 2 (N)表示图中横
坐标.纵坐标为 x11perf 得分(得分值越高,性能也越高).不同颜色的曲线对应不同的私有运行队列长度 M 值.
从图 11~图 19,每一个图都代表一种不同的分屏方案.不同的分屏方案(S x 和 S y )之间对比,一般分屏数量越
多,性能值越高,但超过 4 个分屏后,性能增加明显减少,甚至下降;每一个图内,每一条由相同的运行队列长度 M
对应的曲线,一般都随着 N 的增大其性能逐步提高,但都在大约 log 2 (N)=15 之后便不再明显上升反而有所下降;
每一个图内,在任意 N 值附近,一般 M 越大性能越高,但当 M 超过 1 024 后,性能反而有所下降.
从图 11~图 19 可见:随着屏幕越分越细密(S x 和 S y 增大)以及子进程私有队列越来越长(M 和 N 越来越长),
矩形绘制性能逐步提高,并且测试曲线逐步接近直线,加速比也逐步趋于线性.分析其原因,主要是由于随着屏
幕划分的增多,可以创造出更多的线程,为充分发挥多核 CPU 的性能提供了可能;另外,M 和 N 的增加,也使多线